Continuous Network Monitoring: From Reactive Fixes to Proactive Operations
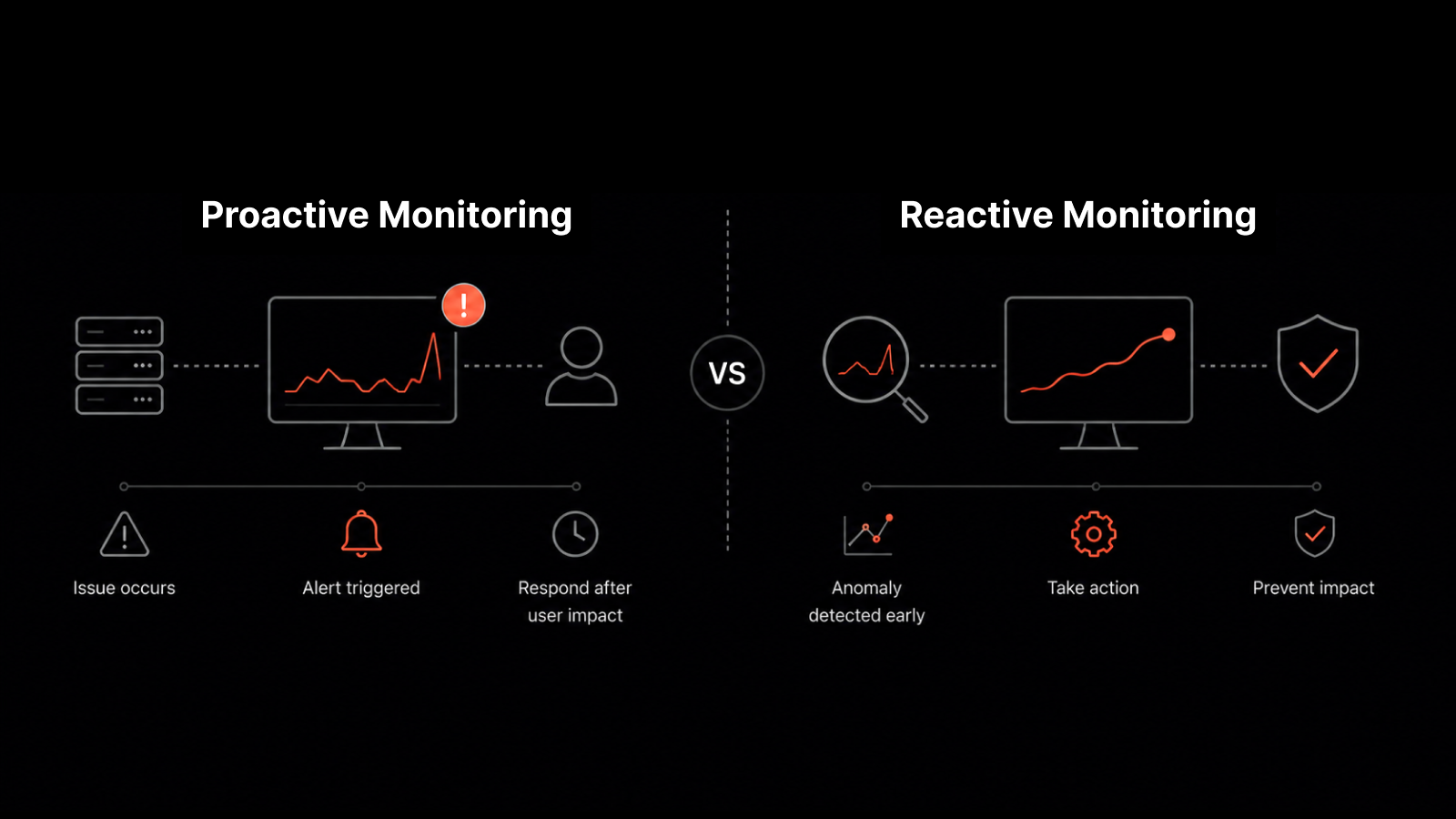
Continuous network monitoring shifts IT operations from chaotic, incident-driven "firefighting" to proactive, automated operations. By leveraging 24/7 continuous observability, this approach anticipates hardware failures, bandwidth bottlenecks, and security vulnerabilities—stopping outages before employees or customers are affected.
Transitioning to proactive operations requires a strategic, phased overhaul of how you track, analyze, and automate your infrastructure:
1. The Operational Shift
• Reactive (Break-Fix): Relies on user complaints, generates high-pressure emergency fixes, and causes unpredictable downtime.
• Proactive (Continuous): Uses baseline data and anomaly detection to spot early warning signs (e.g., unusual memory spikes or packet loss) and fix them during scheduled maintenance.
2. Core Elements of Continuous Monitoring
• Real-Time Visibility: Constant, 24/7 scanning of traffic, bandwidth usage, and device health across on-premises, cloud, and hybrid environments.
• Anomaly Detection: Setting dynamic thresholds that flag deviations in standard network behavior rather than waiting for hard crashes.
• Predictive Analytics: Utilizing AI and machine learning to forecast future issues (e.g., predicting when a switch will exceed its capacity limits based on historical trends).
• Security & Compliance: Actively defending against threats and vulnerabilities while ensuring ongoing regulatory compliance.
3. Key Benefits of Proactive Operations
• Reduced Downtime: Prevents disruptions before they can halt business operations.
• Optimized Performance: Identifies bottlenecks and maximizes resource efficiency.
• Cost Savings: Lowers expenses related to emergency after-hours support, lost revenue, and equipment replacement.
• Strategic IT Planning: Allows IT teams to focus on system growth and architecture rather than daily firefighting.
4. Implementation Steps
1. Gap Analysis: Map your existing tools and identify network blind spots.
2. Telemetry Unification: Centralize logs, metrics, and traces into a single observability platform.
3. Establish Baselines: Use your monitoring tools to learn normal traffic patterns.
4. Automate Remediation: Implement automated scripts or ITSM/CMMS integrations that auto-resolve common, low-level alerts